 КДЕ на српском
КДЕ на српском
Могућности
Врхунац развоја
КДЕ, као пројекат и развојна платформа, пружа најсавршенији техничко-организациони систем за локализацију софтвера. У наредном ће бити илустровани елементи те усавршености који су уочљиви корисницима КДЕ програма, и који непосредно доприносе утиску о потпуности локализације.
Треба нагласити да већина побројаних елемената није својствена искључиво КДЕ-у, али се, за сада, само у КДЕ-у могу наћи сви на окупу. Обратно, сваки од њих недостаје бар у неком преводилачком окружењу.
Контексти
При писању програма, програмери често једну те исту ниску текста користе на више места у сучељу програма; обично су такве ниске врло кратке, попут New, Default, Small и сл. Међутим, овакве ниске су често логички везане за неки други део сучеља које додатно одређују, на пример [Icon size:] Small и [Font size:] Small. Због овога може доћи до тога да превод дате кратке ниске не одговара на свим местима на којима је приказана: „[Величина икона:] мале“ и „[Величина фонта:] мале“, или „[Величина икона:] мали“ и „[Величина фонта:] мали“. Када дође до овога, преводилац може бити принуђен да изабере неки неутралан превод, такав који не одговара најбоље ниједном месту употребе али укупно изгледа најмање ружно.
Преводиоцима КДЕ-а саветује се да не праве компромисе по овом питању, већ да проблем у потпуности разреше, зашта су им на располагању и техничка и организациона средства. Технички, локализациони радни оквир КДЕ-а омогућава додавање контекста уз ниске сучеља, којим се изворна ниска додатно одређује по месту употребе и омогућава њено превођење на више начина. Организационо, преводилац се може обратити директно програмеру да дода контекст уз ниску; може чак и затражити додавање контекста на централној преводилачкој листи, не обративши се ником посебно, и наћи ће се неки преводилац са довољно програмерског умећа да сам дода жељени контекст у програмски ко̂д.
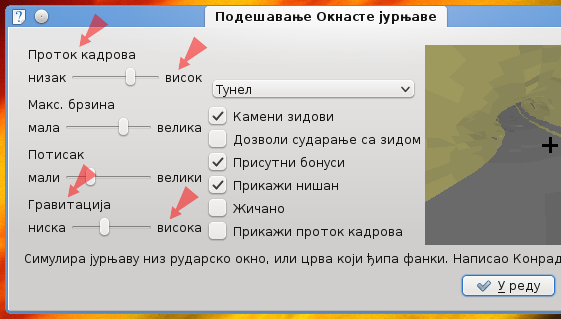
Контексти — преводи истих енглеских ниски на различите начине.
Облици множине
За енглески језик, на коме се изворно пишу програми под окриљем КДЕ-а, карактеристична је врло мала променљивост; у односу на српски, посебно то да нема промене кроз падеже нити слагање придева са именицама по роду, броју и падежу. Ово доводи до тога да је ниску текста у коју се програмски (тј. током извршавања програма) умећу подниске често тешко или немогуће превести граматички правилно.
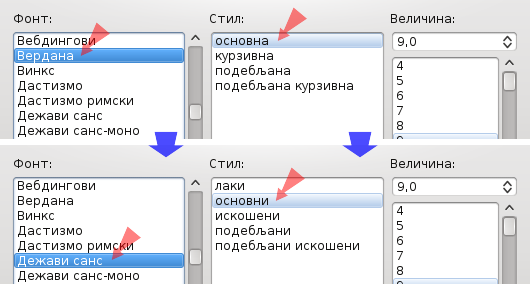
Далеко најчешћи случај програмског уметања које захтева граматичко слагање у окружујућем тексту јесте уметање целог броја: 45 messages deleted, 32 messages deleted, 21 messages deleted. Преводилац овакве ниске добија на превод нешто налик на %d messages deleted, где је %d тзв. местодржач, који се при извршавању програма смењује потребним бројем. Ако би оваква ниска била преведена као „обрисано %d порука“, онда би корисник програма видео граматички исправно „обрисано 45 порука“, али неисправне „обрисано 32 порука“ и „обрисано 21 порука“. Зато је преводилац у неким окружењима често принуђен да иде на рогобатнији облик који не захтева слагање, попут „обрисаних порука: %d“; што је изворна реченица природнија, то изврдавање овог проблема производи извештаченији превод.
Међутим, слагање броја са остатком ниске, тзв. множински облици, у већини језика довољно је просто да се може успоставити формула која сваком целом броју придружује један од малог броја могућих облика. За српски, то су три облика, евентуално четири у појединим случајевима. Локализациони радни оквир КДЕ-а омогућава преводиоцима да задају ову формулу за свој језик, а затим да сваку множинску ниску преведу онолико пута колико облика множине постоји; потом се при извршавању програма узима онај превод који одговара тренутном броју.
Облици множине — слагање речи са бројем у реченици.
Још граматичких облика
За разлику од множинских облика, који су просто дефинисани и лако програмски обрадиви, друге категорије граматичког слагања при извршавању већ су много сложеније. Посебно је тешко извести програмску подршку за један језик тако да не иде на уштрб неког другог језика, да не усложњава поступак превођења на језике где није потребна. КДЕ ипак изводи један такав систем за граматичку подршку, посебну од језика до језика, тако да је само виспреност и умеће преводилаца граница у ономе што се може постићи.
Што се српског језика тиче, најпре су потребна слагања падежа синтагми када се умећу у шири текст, и слагање придева по роду и броју са оним што одређују: „Увези обележиваче из %s“ (местодржач %s се смењује именом прегледача, попут „Фајерфокс“ или „Опера“, потребан генитив имена), „Састанак је померен са %s на %s“ (умећу се два дана у седмици, први треба да је у генитиву а други у акузативу), „Уклони овај %s“ (име информативне алатке, попут „одокативни сат“ или „временска прогноза“, које треба да је у акузативу, али и заменица „овај“ мора да се сложи уз род имена).
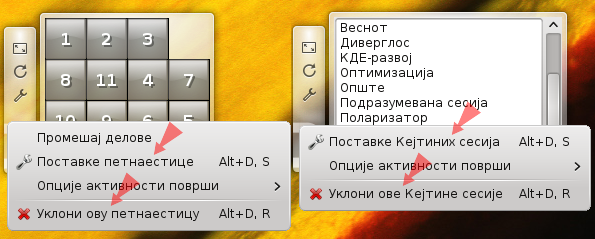
Граматика — слагање уметнутог и околног текста.
Даље од обичног текста
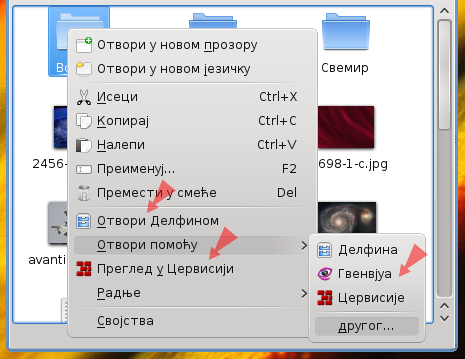
Иако ће многи локализатор устврдити да „локализација није само превођење текста“, у пракси заправо јесте (ако изузмемо елементе попут форматирања времена и датума, бројева, хифенације, и сл. чији је број ограничен и фиксиран). Посебно ручно цртани стилизовани натписи на графичким елементима обично остају нелокализовани. Локализациони радни оквир КДЕ-а обезбеђује начин да се локализују и нетекстуални елементи, где год је то потребно.
Локализована графика — иконе и натписи.
Потпуна подршка језичког стандарда
Српски стандардни књижевни језик састоји се од два наречја и два писма, односно четири равноправне комбинације: екавски ћирилицом, екавски латиницом, ијекавски ћирилицом, ијекавски латиницом. Зато се „потпуном локализацијом на српски“ може назвати само она која кориснику нуди избор било које од ове четири комбинације. Локализација КДЕ-а је управо једна таква.
Ово не значи да је за превођење КДЕ-а потребно четири пута више времена него што би то било за само једно наречје и писмо. Уместо тога, развијена је техника превођења која омогућава да се на одржавање све четири варијанте превода троши тек око 10%–15% више времена него на само једну. Притом, ћириличке и латиничке варијанте не разликују се само слово за слово, већ је подржана данашња претежна пракса да се страна имена у латиничким текстовима рачунарске тематике преносе у изворном облику.
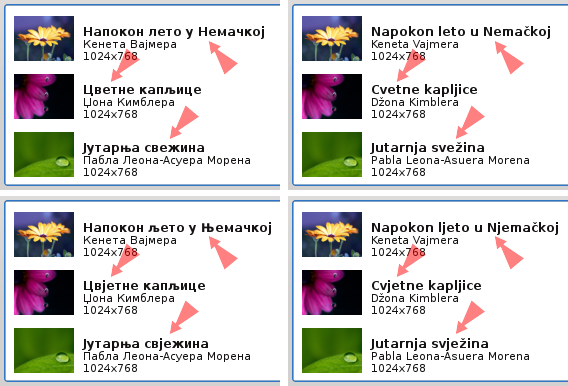

Пун језички стандард — комбинације наречја и писма.
Праћење прилагођених имена
Страна имена се често прилагођавају при преношењу у српски језик, на један од два начина: транскрипцијом (по изворној звучности и писму) и превођењем (по изворном значењу и аналогији). При употреби прилагођених имена често је корисно читаоцу представити и изворне облике на неки начин. Ово је тим важније за текстове некњижевне природе где су корисници у могућности и вољни да истражују даље за именима на страном језику, што је управо случај са преводима сучеља и документације рачунарских програма.
Рачунарски текстови су додатно посебни по томе што често нису линеарни — немају тачно одређеног почетка ни краја — или се не ишчитавају тако и кад јесу, па је од мале користи наводити изворно име при „првом помињању“ прилагођеног имена. Због овога се при превођењу КДЕ-а сва прилагођавања темељно бележе, тако да их корисник може наћи на списку „транскрипција и превода назива и акронима“ — трапнакрону — на адреси http://sr.l10n.kde.org/trapnakron/.
Штавише, изворно име се може пронаћи из прве управо на истом путу којим се најчешће креће у даље истраживање, уношењем упита „трапнакрон прилагођено_име“ у неки од претраживача Интернета попут Гугла.
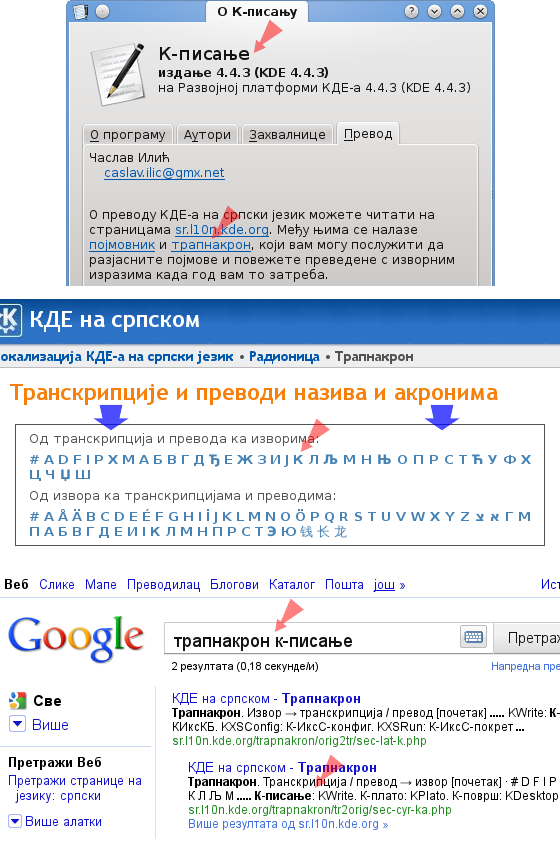
Изворни називи иза транскрипција и превода — директно или преко претраживача.
Истовременост са енглеским издањима
У пројекту КДЕ-а, преводи се сматрају нераздвојним делом програма, као једна од њихових основних одлика. Овакав став потиче отуд што су и програмери у КДЕ-у са свих крајева света, и многима од њих је стало да они сами и њихова околина користе програме на свом језику. Зато је динамика издавања уређена тако да се преводиоцима увек даје довољно времена да допуне преводе, како би свако издање програма стизало истовремено на свим језицима на које је преведен. Не постоји временска задршка између издања на енглеском, затим на „важнијим“ језицима, те коначно на оним „мање важним“. С техничке стране, не постоје „потпуне“ и „делимичне“ локализације, већ степен локализације за неки језик зависи само од ангажованости његових преводиоца.
Овако корисници, посебно они који радо инсталирају нова издања чим се појаве, не бивају принуђени да бирају између најновијег али нелокализованог и старијег локализованог издања.

Почетак једне типичне објаве издања Софтверске компилације КДЕ-а.
{kind=link}